 |
| TERN OzFlux has developed a data processing tool called OzFluxQC that is making it easier for the Australian research community to access the wealth of flux data being generated by OzFlux’s national network of flux monitoring towers (above) and facilitating data processing at all three stages in the OzFlux ‘data path’ (below): data collection, data quality control and processing, and data delivery to researchers. |
|
A new ‘behind the scenes’ data tool produced by TERN OzFlux is making it easier for researchers to access and download nation-wide data on the exchanges of heat, water and carbon dioxide between terrestrial ecosystems and the atmosphere. Data that are essential for improving our understanding of the response of Australian ecosystems to climate variability, disturbance (fire, insects), land management and future changes in precipitation, temperature and carbon dioxide levels.
Twenty years ago, the exchanges, or fluxes, of heat, water and carbon dioxide between terrestrial ecosystems and the atmosphere could only be measured by researchers working in the field for short periods at a time. The resulting flux data was both spatially and temporally patchy. Advances in instrumentation have now made it possible to make landscape observation remotely, 24 hours a day, 365 days a year. Equipment costs have also fallen, making it possible to replicate these observations across many ecosystems. Today, an international network of high-tech flux measuring towers enables us to watch continents breathe in and out, every day, over all seasons and across the changing years.
The global flux measuring network, called FluxNet has about 500 sites and the Australian component, OzFlux, has about 25 sites. So many sites measuring multiple land-atmosphere fluxes all day every day means there is a staggering amount of data being produced. New robust tools were needed to reduce the overheads of data processing, facilitate standardization across multiple sites, and enable researchers to access and reuse the data.
To meet these flux data needs in Australia, OzFlux has developed a data processing tool called OzFluxQC. OzFlux’s Data Manager Peter Isaac says that the primary motivation behind the new tool was to make it easier for the Australian research community to access the wealth of flux data being generated by OzFlux’s national monitoring network.
‘The system we’ve developed is relatively easy to learn, embodies the knowledge gained by Australian researchers and makes it easier to get data out to end users,” said Peter. “These were our primary motivations when developing the OzFlux data path.”’
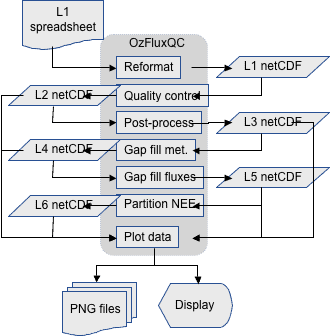
Produced by OzFlux community members over the last 4 years, OzFluxQC provides an integrated, GUI-based environment for the processing and publishing of OzFlux data. It facilitates data processing at all three stages in the OzFlux ‘data path’: data collection, data quality control and processing, and data delivery to researchers. At all stages of this path, OzFlux has sought to use standard methods and names to reduce the time taken processing the data and to make the end product consistent across the network. This is helped by the fact that the data stream from the OzFlux sites is very homogeneous allowing the same methods to be used across the network.
The first step along the OzFlux data path (called L1 – see image at right) is to convert the raw data from the flux towers to an internationally recognized and accessible format called netCDF. The netCDF format was chosen because it: 1) stores important metadata about both the site and the variables; 2) allows the data to be exposed to a wide audience via web-based applications such as OPeNDAP and THREDDS; 3) is well supported by all scientific programming languages; and 4) has a large user-base among the global modelling community. OzFlux has adopted the Climate and Forecasting (CF) Metadata conventions so that variables within OzFlux netCDF files can be identified by a variable attribute chosen from a controlled vocabulary. Researchers using OzFlux data need only know that the files are netCDF and conform to the CF Metadata conventions in order to be able to use the data for standard analyses.
Levels 2 and 3 of the Ozflux data path are concerned with quality control and post-processing. Data at this level is ready for use by other groups such as the global FluxNet community, but may still contain gaps due to instrument failures. These gaps must be filled before monthly, annual and multiple-year water and carbon budgets can be calculated for the sites.
Gap filling is done in two stages in the Ozflux data path. Level 4 (L4) fills gaps in the meteorological data using three alternative data sources. Atmospheric pressure, temperature, humidity, wind speed, wind direction and precipitation can be taken from the nearest Bureau of Meteorology’s Automatic Weather Station (AWS) site or from the output of the Bureau’s numerical weather prediction (NWP) model, ACCESS-G, running at 12.5 km resolution across Australia. The ACCESS-G data also contains incoming and outgoing short- and longwave radiation, soil temperature, soil moisture and ground heat flux which are not available from the AWS network. For sites established before the ACCESS-G data became available, OzFlux uses similar data that has been generated for use with the CSIRO’s BIOS2 land surface model.
Level 5 (L5) uses a neural network to fill gaps in the flux measurements. The neural network is first trained on the ‘gappy’ L3 meteorological (driver) and flux (target) data, and then applied to the L4 data to predict the missing flux observations using the gap filled meteorological drivers. Neural networks have proved to be better predictors of the fluxes than process-based models but they are not infallible, and OzFluxQC allows their operation to be carefully supervised by the user.
The final stage in the processing is to partition the gap-filled carbon dioxide flux (net ecosystem exchange or NEE) into its components of photosynthetic uptake (gross primary productivity or GPP) and respiration loss (ecosystem respiration or Reco). Reco is estimated from nocturnal NEE after removing periods when the measurements are unreliable due to low turbulence, using the change point detection method to identify site-specific turbulence thresholds. Ecosystem respiration is then predicted for the missing times (day time and rejected night time) using a neural network, with soil temperature and soil moisture as drivers, or a process-based model using only soil temperature.
In addition to the data processing stages, OzFluxQC offers utilities for converting files between formats (netCDF, Excel and comma separated value text files) and for displaying the data as time series and images of both 30 minute and daily data.
Data from OzFluxQC at L3 to L6 is uploaded by site PIs to the OzFlux Data Portal which is hosted on NeCTAR virtual machines (VMs) using storage from RDSI. Separate applications on the OzFlux VMs run an OAI-PMH data provider and an OPeNDAP/THREDDS server. The OAI-PMH provider allows harvesting of RIF-CS files making the OzFlux data collections visible to the TERN Data Discovery Portal and Research Data Australia. The OPeNDAP/THREDDS server allows any DAP-aware application to access OzFlux data via the internet as though the files were on the user’s local machine, avoiding the need to always download the most recent version of a data set.
- For more information on the OzFlux data path please contact Peter Isaac.
- To explore data from OzFlux’s national network of flux monitoring towers click here.
Published in TERN newsletter March 2015
